
Sometimes, existing commercial or out-of-the-box open-source tools like Grafana don’t fit requirements for Nginx log analytics. Whether it is pricing, privacy, or customization issues, it is always good to know how to build such a system internally.
In the following tutorial, I’ll show you how to build your own Nginx log analytics with Fluentd, Kinesis Data Firehose, Glue, Athena, and Cube.js. This stack also makes it easy to add data from other sources, such as Snowplow events, into the same S3 bucket and merge results in Athena. I’ll walk you through the whole pipeline from data collection to the visualization.
Here is the live demo of the final dashboard.
Here’s a sample architecture of the application we’re going to build:
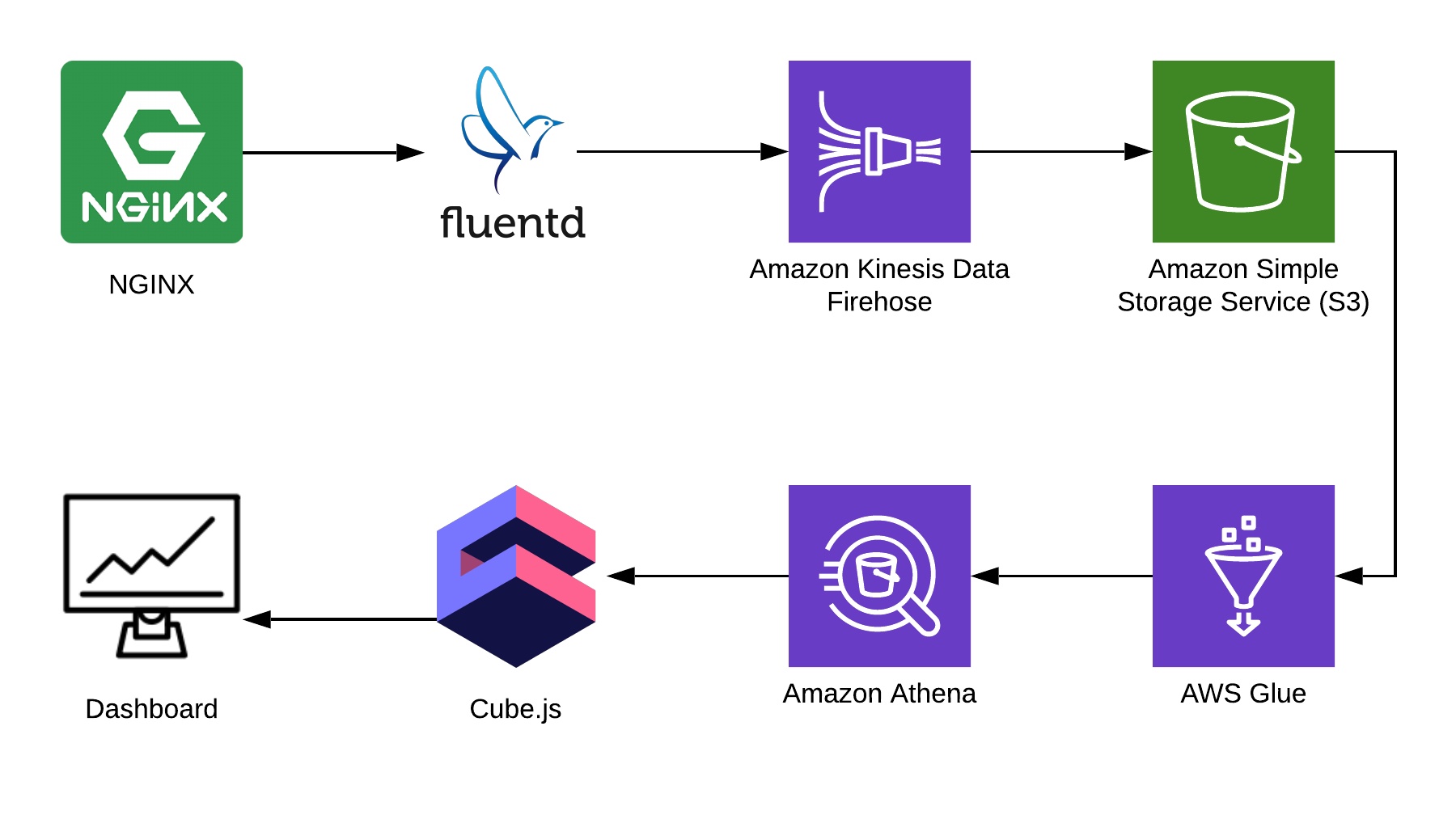
Collecting Nginx Logs
By default, Nginx writes logs in a plain text format like this:
Although we can parse that, it would be much easier to change Nginx configuration to use the JSON format.
Create an S3 Bucket
Create a new S3 bucket for the log files. Note that logs should be placed in the root of the bucket and no other data can be stored in that bucket. Also, consider using the same region as your Athena because Athena is not available in some regions.
Define a Table Schema via the Athena Console
Open your Athena console and select the database you'd be using. To create a table, you can use AWS UI or just run create statement in the console.
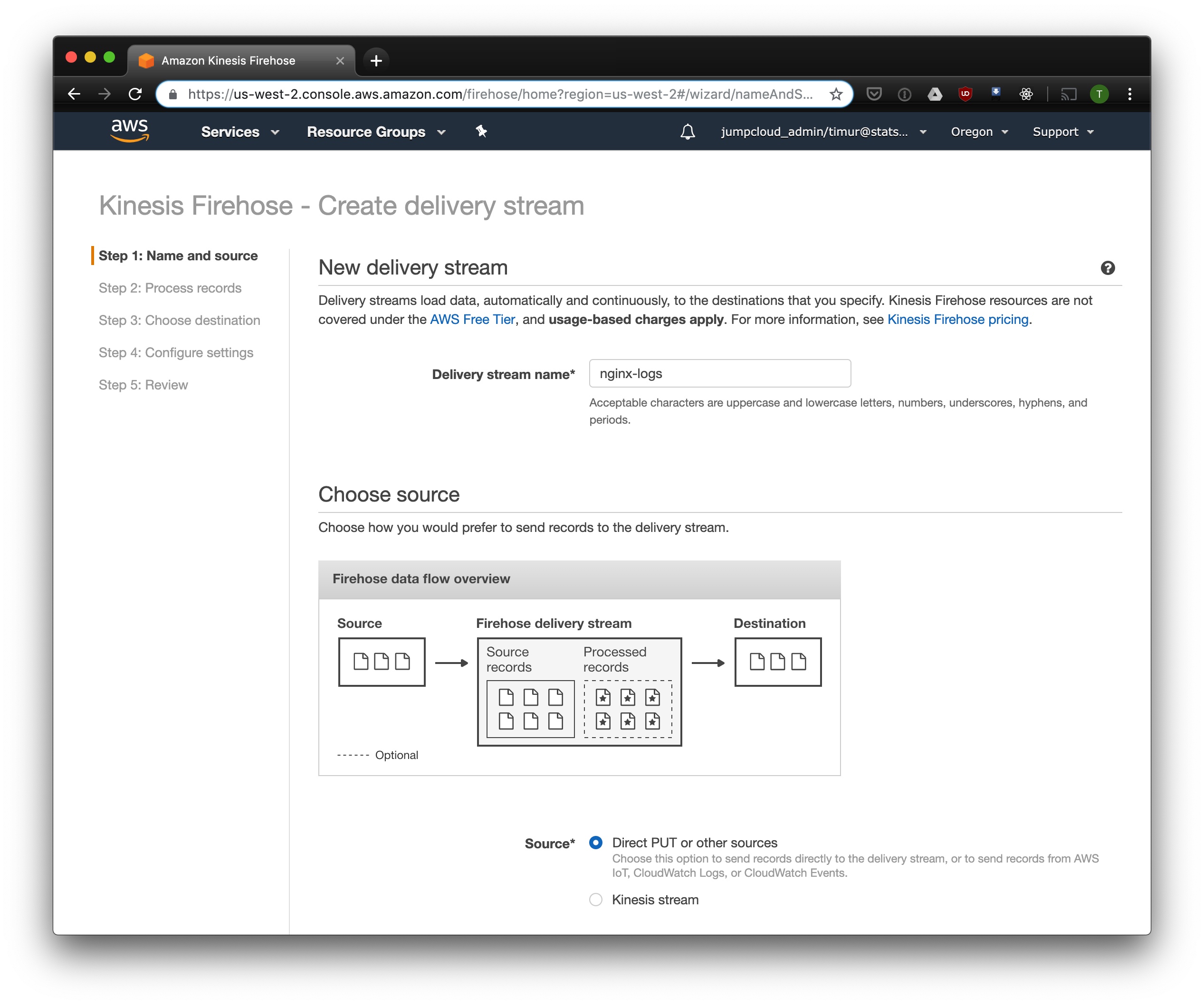
Create a Kinesis Firehose Stream
Open up the Kinesis Firehose console and click "Create delivery stream." Enter a name for the stream and set delivery to direct PUT.
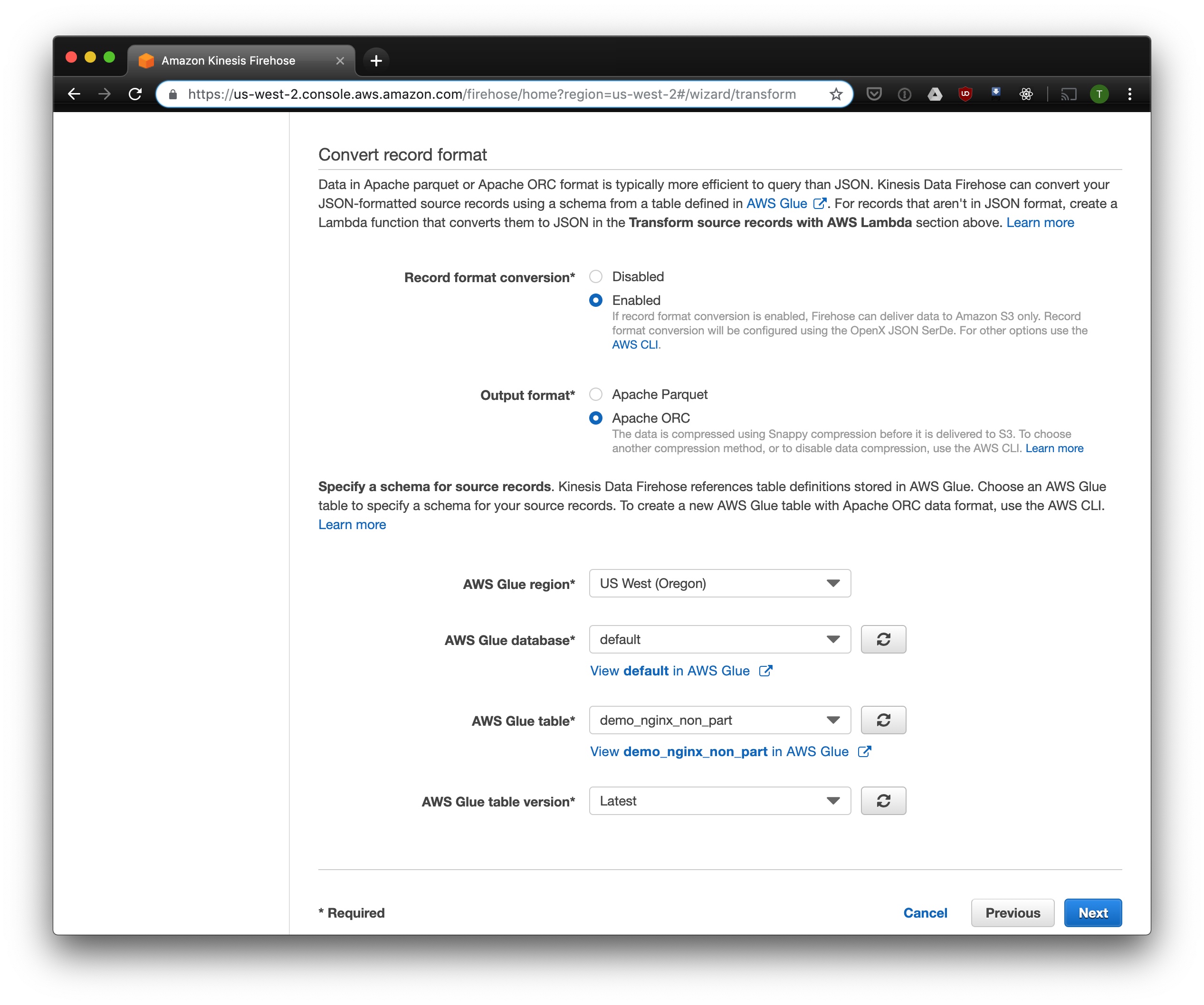
Click next. Select Record format conversion to Enabled, Output format to Apache ORC, and select the database you created as the schema source.
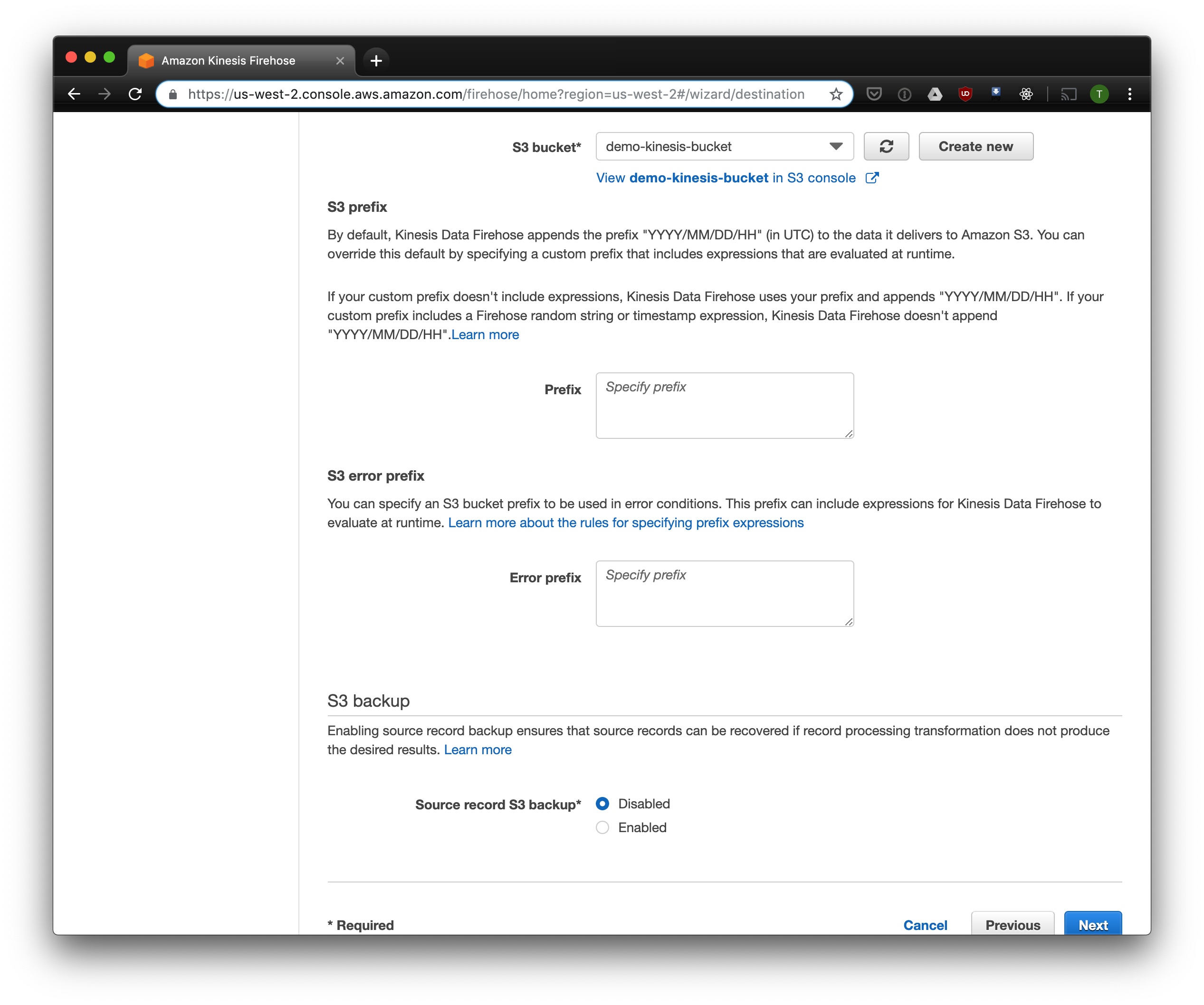
Select S3 as a storage format. Select the S3 bucket you created for log files and leave S3 Prefix empty.
You can change other options depending on your load, but we'll continue with the default ones. S3 compression is not available since the ORC format includes compression. Now you've created the Kinesis Firehose stream!
Fluentd
There are many different ways to install and use Fluentd. We'll stick with the Docker version.
First, create a fluent.conf file and add a new Fluentd source to collect logs:
Now we can run a Fluentd server with this configuration. Here's a basic configuration; you can check out other options on Docker Hub.
This configuration uses the /fluentd/log path for cache files. You can run Fluentd in Docker without mounting the data directory, but in the case of a restart, you can lose all cached logs. Also, you can change the default 24224 port to any other unused port. Now, as we have a running Fluentd server, we can stream Nginx logs to it.
Since we run Nginx in Docker, we can run it with the built-in docker Fluentd log driver:
We'll use the Amazon Kinesis Output Plugin. It can store logs captured from Nginx as ORC files.
Next, select the Nginx log using tag prefix match and parse JSON:
We’re using the kinesis_firehose output plugin to send parsed logs to Kinesis Firehose:
Athena
Now you can query Nginx logs in Athena with SQL. Let's find some recent errors:
Full Scan for Each Request
Now we have logs parsed and delivered to S3 in the ORC format, which is compressed and efficient to query. Also, Kinesis Firehose partitions logs by date and hour, but querying and filtering them requires Athena to scan all files. This is a problem, because the more logs you store, the more data gets scanned per request. It is slow and also pricey, because Athena pricing depends on scanned data volume.
To solve this, we'll use AWS Glue Crawler, which gathers partition data from S3 and writes it to the Glue Metastore. Once data is partitioned, Athena will only scan data in selected partitions. It makes querying much more efficient in terms of time and cost.
Setting an Amazon Glue Crawler
Amazon Glue Crawler can scan the data in the bucket and create a partitioned table for that data.
Create a Glue Crawler and add the bucket you use to store logs from Kinesis. You can add multiple buckets to be scanned on each run, and the crawler will create separate tables for each bucket. Make sure to schedule this crawler to run periodically depending on your needs. We usually run a single crawler for all buckets every hour. Also, it's easier to use a separate database for all crawled tables.
Partitioned Tables
Open your Athena console and choose the database you selected in the crawler configuration. After the first run of the crawler, you should see a table named the same as the S3 bucket where all log files are located. You can query results for some hours and filter the data by partitions.
This query will select all events that came from 6 AM to 7 AM on April 8, 2019.
Did that help? Let's run the same request without a partition filter.
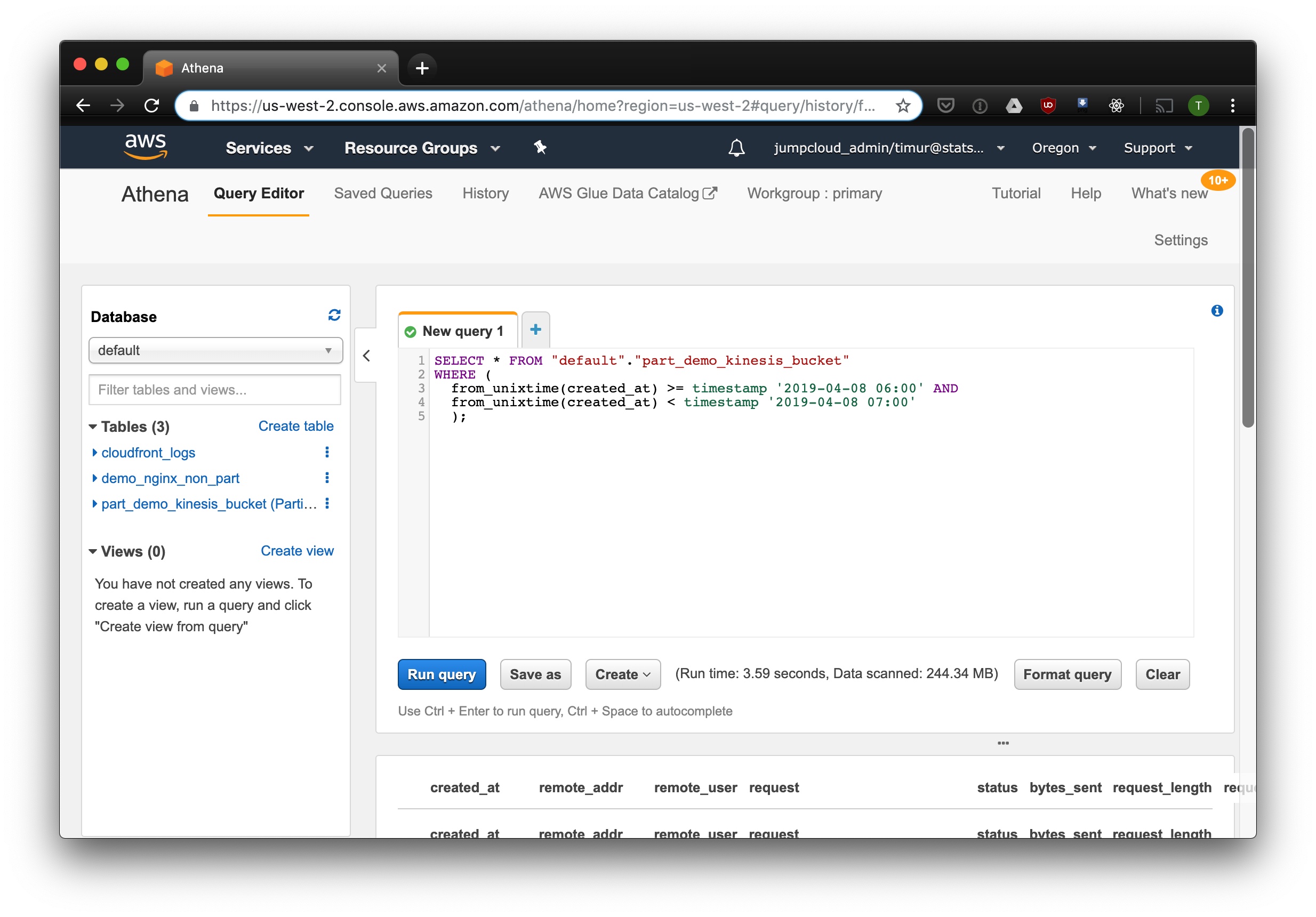
You can see that the query took 3.59 seconds to run and processed 244.34 megabytes of data. Let's use partition helpers:

This query is a bit faster and, more importantly, took only 1.23 megabytes of scanned data. On larger datasets, the difference grows dramatically.
Building a Dashboard with Cube.js
We will use Cube.js to query Athena and build a dashboard. It has plenty of powerful features, but the main reasons we would want to use it, in this case, are automatic handling of partitions and pre-aggregations.
Cube.js can dynamically generate SQL, taking care of partitioning. It uses data schema, which is written in Javascript, to generate SQL. We can put instructions on how to filter partitions in the data schema.
Let’s create a new Cube.js app with a serverless deployment option. Since we’re using Athena, serverless is the easiest way to deploy. If you prefer other deployment environments, such as Docker or Heroku, you can check the documentation on deployment options here.
Cube.js uses environment variables for database credentials. On new app creation, the CLI generates the .env file with placeholders in the project directory. Fill it with your Athena credentials.
Now, we can create a data schema file, where we’ll define how Cube.js should query the Athena logs table, as well as measures and dimensions for our dashboard. If you are just getting started with Cube.js, I recommend checking this or that tutorial to learn more about data schemas and how Cube.js generates SQL.
In the schema folder, create the file Logs.js with the following content:
In the top level sql expression for the Logs cube, we are using the FILTER_PARAMS feature of Cube.js to dynamically generate SQL based on the passed filter parameters.
We also define measures and dimensions we’ll use in our dashboard. One last thing to do before building a frontend is to set up pre-aggregations. The Cube.js pre-aggregation engine builds a layer of aggregated data in your database during the runtime and keeps it up-to-date. It can significantly speed up the performance and also in the case of Athena reduce billing as well. This guide covers using pre-aggregations in more details.
To add it to our schema, add the following block to the end of the cube definition.
We’re pre-aggregating all the measures and dimensions we’ll use and also making this pre-aggregation to be partitioned by month. Partitioning pre-aggregations can dramatically increase background refresh time.
Now, we are ready to build our frontend dashboard.
Cube.js provides REST API, a Javascript client, and bindings for popular frameworks, such as React and Vue. The clients are visualization agnostic and take care of API calls and data formatting, letting developers use any visualization library.
The Cube.js server accepts a query in a JSON format with measures and dimensions. It then generates and executes SQL against Athena, and sends the result back. For example, to load the count of requests with an error over time by day, we can use the following request:
You can install the Cube.js Javascript Client and React binding with NPM.
Then import the cubejs and QueryRenderer components, and use them to fetch the data. In the example below, we use Recharts to visualize data.
This tutorial goes into great detail on how to build dashboards with Cube.js.
You can find a CodeSandbox with a demo dashboard built with React and Cube.js below.