
For the last couple of years, we’ve been working on Cube.js, an analytics framework built specifically for customization and embedding. There are a lot of great tools data engineers can use to build internal data infrastructure. But there is a lack of tools for software engineers who are building production, customer-facing applications and need to embed analytics features into these applications.
The major requirements we had were to make it easily scale to large datasets while allowing full UI customization on the frontend. It also had to be dependencies free and especially not require wiring up a complex infrastructure of data pipeline jobs.
It has been in production in multiple companies for more than a year already with petabyte-sized datasets. Feeling confident that Cube.js is doing its job, we open sourced it 4 months ago for a broader audience to use. In this article, I want to share a detailed description of Cube.js’s architecture and why we designed it this way. After reading it, I hope you try out Cube.js for your own analytics applications!
The schema below shows how Cube.js is typically deployed and embedded into the existing application architecture. The Cube.js backend microservice is connected to one or multiple databases, taking care of database queues, data schema, caching, security, and API gateway. The client loads aggregated data from the backend, processes it, and sends it to the visualization library of your choice.
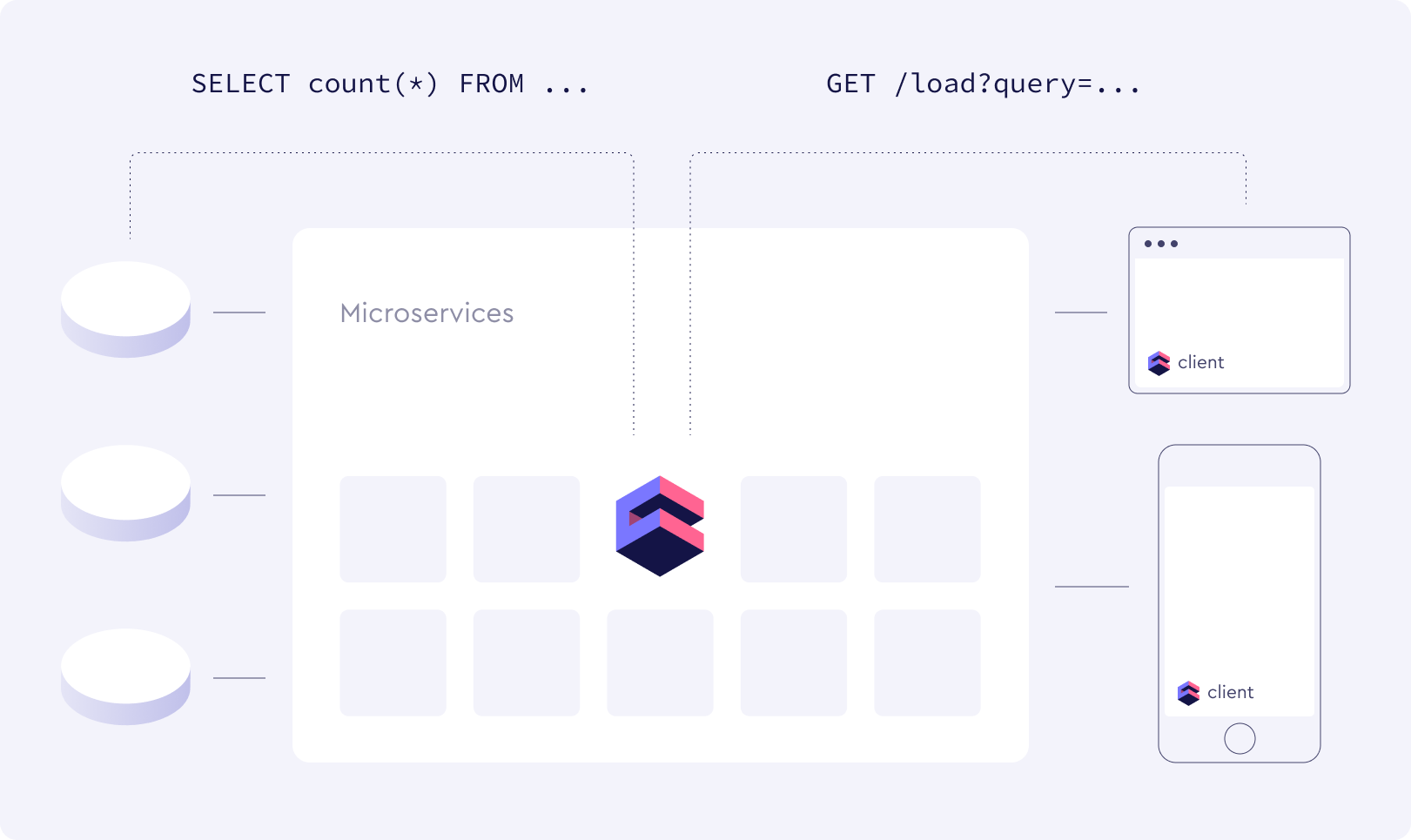
Below I’ll put a detailed description of what exactly happens in both the backend and the client, but first I’d like to highlight the most important decisions we made when designing Cube.js.
Data Schema
ORMs are quite ubiquitous in software development, but when it comes to analytics, it usually ends up with tons of SQL scripts and templates. The idea behind data schema is to take the best practices of ORM and apply them to analytics use cases. We’ve grabbed an good-old idea of multidimensional analysis with measures and dimensions as abstraction entities and de-facto created a ROLAP (Relational OLAP) engine, which transforms measures and dimensions into SQL code.
The biggest thing about the data schema is that we made it fully dynamic. A data schema in Cube.js is not an XML/JSON-like static thing but is a JavaScript code, which means you can dynamically generate it. You can even load your measures or dimension definitions from a database or over API during the runtime.
Having the schema in place is vital to providing abstracted and flexible query language for API clients. No one wants to send SQL code or SQL snippet IDs over the API, so the query language is eventually developed in every case of such a system. That is why we made Cube.js come with it already and backed it by OLAP best practices.

In Database Pre-Aggregations
Although we have a usual last-mile in-memory cache, pre-aggregations make a big difference when it comes to performance, especially for dynamic queries. Cube.js can create reusable aggregate tables in your warehouse, which are extremely fast to read. One aggregate table usually serves multiple queries. Cube.js also takes care of refreshing the aggregate tables when new underlying data comes in.
Cube.js can also automatically calculate and build the required aggregate tables based on the patterns of requested measures and dimensions. We use principles of the data cubes lattice for this and we’ll cover the math behind it in future blog posts. Additionally, you can store aggregate tables in a separate warehouse, e.g. MySQL, when all the raw data could be in BigQuery. That would give you a sub-second response, which is not possible even on small datasets with BigQuery due to its design.
Pre-aggregations are essential for scaling. You can think about it as the “T” in the “ETL.” But the transformation happens inside your warehouse, fully orchestrated by Cube.js.
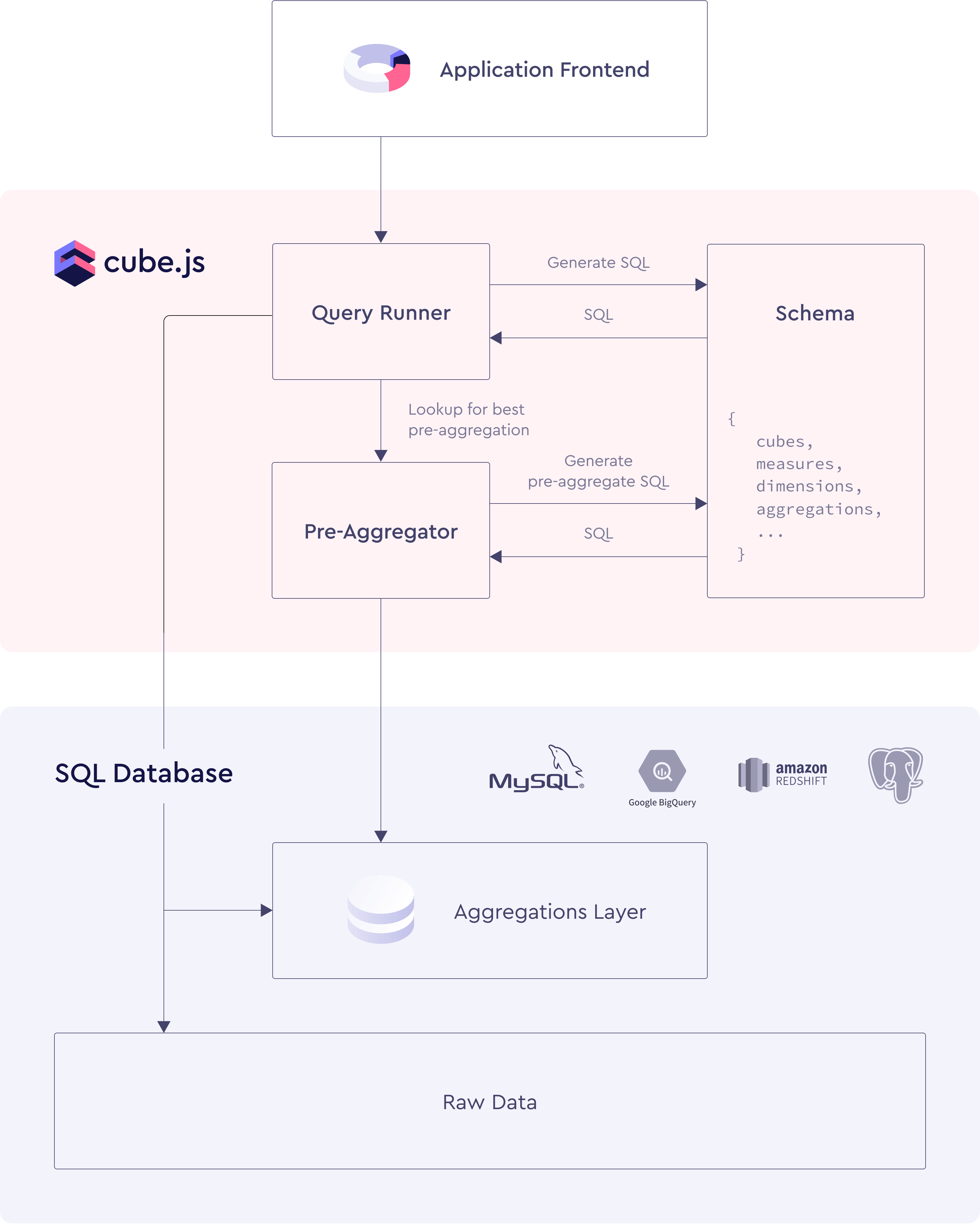
Visualizations Agnostic
This one falls into the category “saying no to the feature is a feature itself.” There are tons of good and mature visualization libraries, so the best we could do is not to invent a new one, but to make sure we play nice with all of them. Although Cube.js doesn’t render anything, it provides a set of useful helpers to post-process data after it is loaded from the backend. It includes things like pivot operations and filling in missing dates. I’ll talk about it later in more detail when describing the components of the Cube.js frontend client.
In the rest of this post, I’ll cover the components of the backend and the frontend.
Cube.js Backend
The backend itself is a Node.js application, which can be configured via environment variables or by writing some Javascript code for more complex use cases. It also needs a data schema, which is a JavaScript code describing how your measures and dimensions should be mapped into SQL. The schema also contains rules for caching, security, and pre-aggregations. The backend is usually deployed as a microservice in your cluster. It has a connection to the required databases and exposes an API either externally directly to clients or internally if you have some proxy for clients.
We’ve designed Cube.js as a modular framework with 4 main components. Usually, they are all used together, but you can use whatever you need in your specific use case. Below I’ll outline each component of the backend and what problems it solves.
Schema Compiler
Schema Compiler compiles a data schema, which is a JavaScript code and based on it and the incoming query generates a SQL code. The SQL code is then sent to Query Orchestrator to be executed against the database. The data schema allows the creation of well-organized and reusable data models. Since it is JavaScript, you can dynamically create all required definitions, extract common pieces into helpers, and in general apply the best engineering practices to organize the data according to business definitions.
A schema is also a place where row-level security is defined. The user context can be passed with every request to Cube.js and propagated to the schema level. In the schema, you can use the user context to restrict access for specific users only to specific data.
Pre-aggregations, a widely used Cube.js feature for big data sets, are also defined in the schema. In that case, Schema Compiler generates not a single query, but a list of dependent queries to build pre-aggregations first and then the final query to fetch the data.
Query Orchestrator
Query Orchestrator’s job is to ensure that the databases are not overloaded and that multi-stage queries are executed and refreshed in the correct order. To do that, it maintains query execution queues for pre-aggregations and data queries. The queues are idempotent, meaning that if multiple identical queries come in, only one will run against the database. The queries are executed by database drivers. As of today, Cube.js supports more than ten native database drivers and a generic JDBC driver.
For multi-stage queries, which is always the case when using pre-aggregations, the query itself consists of multiple pre-aggregations and the final query to fetch the data. Orchestrator makes sure that all the required aggregate tables are fresh and exist before the final query. If the aggregate table does not exist or is outdated, it will schedule a query to create or update it.
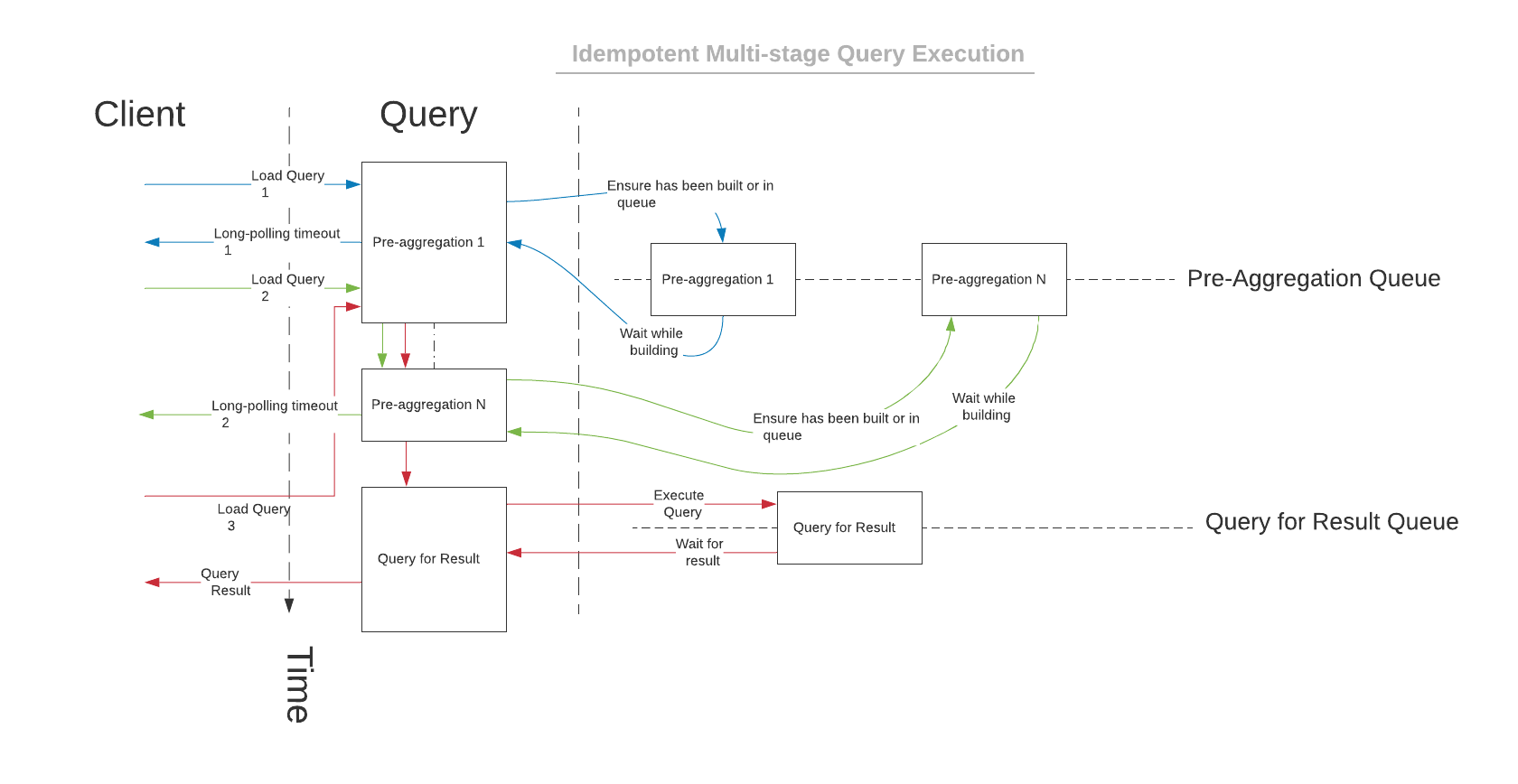
The background refresh of the aggregate tables is abstracted as the async process and could run either inside the standalone application or in the serverless mode. It also optionally allows you to extract the background processing into multi-tenant clusters.
API Gateway
API Gateway defines API endpoints to execute queries, load the metadata, and to inspect SQL generated by the schema compiler. The Gateway implements a long-polling idempotent API to load query results. It makes it tolerant of connectivity issues and guarantees the response without request time frame limitations.
The Gateway is responsible for authentication and authorization as well. By default, the security in Cube.js is implemented with JWT tokens. Every request is signed with a JWT token optionally containing information about security context to be passed to the data schema. The default security model can be overridden with custom middleware if you want to load your security context from a database or specific microservice.
Server Core
Server Core wires all the above components together and exposes a single configuration entry point.
Server Core can be embedded into existing Node.js applications. To launch Cube.js as a standalone application, you need to use the server package; for serverless mode—the serverless package.
Cube.js Client
The Cube.js client is a JavaScript library that works with Cube.js API and post-processes query results. The Core client is a vanilla JavaScript library, which you can run in a browser or on a mobile device if you are using tools like React Native. Additionally, we ship packages for React, Angular, and Vue.js to make it easy to integrate the Cube.js client into these frameworks.
The Cube.js client abstracts the transport layer of loading data from the Cube.js backend and handles loading and error states as well. Once the data is loaded, the client provides a set of helper methods to post-process data. The client provides a pivot interface for displaying data in charts or tables; it also has methods for metadata manipulation and some utilities, like filling in missing dates.
We intentionally left out the visualization part. We had this idea from day one—to build a framework that takes care of everything except visualizations. It seems to be the best combination of power and customization for end users.
Ecosystem
Those were the core components of both the Cube.js backend and frontend. But as a community evolving around the framework, I’m happy to see how the ecosystem grows. The ecosystem of integrations, tutorials, and examples is as important as the tool itself. I’m so grateful for all of the contributions we’ve had from our amazing open-source community already—database drivers, frontend frameworks’ bindings, tutorials, and code samples.
If you are interested in Cube.js and want to contribute—I’d love to see you in our Slack community. It is an ideal place to get started with Cube.js in general and start contributing as well.